7. Kinetic proofreading¶
(c) 2019 Justin Bois and Michael Elowitz. With the exception of pasted graphics, where the source is noted, this work is licensed under a Creative Commons Attribution License CC-BY 4.0. All code contained herein is licensed under an MIT license.
This document was prepared at Caltech with financial support from the Donna and Benjamin M. Rosen Bioengineering Center.

This lesson was generated from a Jupyter notebook. Click the links below for other versions of this lesson.
At the center of many of the genetic circuits we have discussed thus far are the processes of the Central Dogma, notably transcription and translation. The error rate in translation of mRNA to protein by ribosomes is about $10^{-4}$ errors per amino acid. In this lesson, we will work out whether or not this error rate is high or low, and then discuss mechanisms about how it is achieved.
The design principle we will explore is more general: Driven multistep pathways enable amplification of selectivity. By the word "driven," we mean energy consuming reactions are necessary for the multiple steps.
A simple model for incorporation of amino acids¶
We can think of the process of translation as consisting of two successive steps. First, a tRNA (T) reversibly associates with the ribosome/mRNA complex (R). When associated, an amino acid can be irreversibly added to the nascent peptide. This is represented by the following reaction scheme.
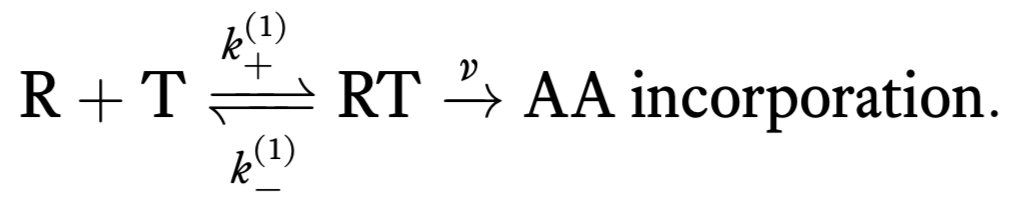
Unfortunately, there can also be incorporation of erroneous tRNAs and we can also get erroneous amino acid incorporation. So, we should really write two sets of chemical reactions, one for correct incorporation of an amino acid and one for erroneous.

Here, we have denoted chemical rate constants for erroneous incorporation with a $p$. Note that we have assumed that the irreversible incorporation rate is the same for correct and incorrect incorporation.
Dynamical equations¶
Using mass action kinetics, we can write the dynamical equations for amino acid incorporation. Importantly, we have
\begin{align} &\text{rate of incorporation of correct AAs} \equiv r_c = v\, c,\\[1em] &\text{rate of incorporation of erroneous AAs}\equiv r_e = v\, e, \end{align}where $c$ is the concentration of RC and $e$ is the concentration of RE. We assume a separation of time scales, where incorporation of the amino acid is much slower than the other dynamics. Thus, the rate of incorporation of amino acids is proportional to the steady state concentration of RC complexes (or RE complexes for erroneous addition). We can write differential equations for $c$ and $e$.
\begin{align} \frac{\mathrm{d}c}{\mathrm{d}t} &= k_+^{(1)} \, c_\mathrm{R} \, c_\mathrm{C} - k_-^{(1)} \,c,\\[1em] \frac{\mathrm{d}e}{\mathrm{d}t} &= p_+^{(1)} \, c_\mathrm{R} \, c_\mathrm{E} - p_-^{(1)} \,e, \end{align}where $c_\mathrm{R}$ is the concentration of ribosomes, $c_{C}$ is the concentration of correct tRNA and $c_{E}$ is the concentration of erroneous tRNA. There are assumed to be constant, since they are in great excess and the cell is constantly producing them. So, in treating the dynamics, we only need the two above ODEs.
Error rates¶
We are interesting in computing the error rate, $f_0$, which is the number of erroneous amino acids incorporated per correct amino acid. We will compute this at steady state, so the steady state error rate is
\begin{align} f_0 = \frac{\text{rate of incorporation of erroneous AAs}}{\text{rate of incorporation of correct AAs}} = \frac{e}{c}. \end{align}So, we just have to compute the steady state values for $c$ and $e$. To do this, we take $\mathrm{d}c/\mathrm{d}t = \mathrm{d}e/\mathrm{d}t = 0$ and solve. We get
\begin{align} c &= \frac{k_+^{(1)}}{k_-^{(1)}}\,c_\mathrm{R}\,c_\mathrm{C}\\[1em] e &= \frac{p_+^{(1)}}{p_-^{(1)}}\,c_\mathrm{R}\,c_\mathrm{E}. \end{align}Thus, the error rate is \begin{align} f_0 = \frac{e}{c} = \frac{p_+^{(1)}}{p_-^{(1)}}\,\frac{k_-^{(1)}}{k_+^{(1)}}\,\frac{c_\mathrm{E}}{c_\mathrm{C}}. \end{align}
Note that the two ratios of rate constants are the dissociation constants for the interaction of the tRNA with the ribosome/mRNA complex; $K_\mathrm{d,c} = k_-^{(1)}/k_+^{(1)}$ and $K_\mathrm{d,e} = p_-^{(1)}/p_+^{(1)}$. Finally, to ease notation, we define the ratio of concentrations of erroneous and correct tRNAs to be $q$. Thus, we have
\begin{align} f_0 = q\,\frac{K_\mathrm{d,c}}{K_\mathrm{d,e}}. \end{align}From thermodynamic considerations, the dissociation constant is given by
\begin{align} K_\mathrm{d} = \exp\left[-\frac{E_\mathrm{R} + E_\mathrm{T} - E_\mathrm{RT}}{k_BT}\right], \end{align}where T is either E or C. Since $E_\mathrm{C} \approx E_\mathrm{E}$, the ratio of the dissociation constants is
\begin{align} \frac{K_\mathrm{d,c}}{K_\mathrm{d,e}} = \exp\left[-\frac{E_{\mathrm{RE}} - E_{\mathrm{RC}}}{k_BT}\right]. \end{align}So, the error rate for this simple model is
\begin{align} f_0 = q\,\exp\left[-\frac{E_{\mathrm{RE}} - E_{\mathrm{RC}}}{k_BT}\right]. \end{align}Does this work?¶
As mentioned before, about $10^{-4}$ erroneous amino acids per residue are incorporated. We will take $q \approx 20$, though this can vary significantly depending on the amino acid, since tRNA abundance is variable. So, to get an error rate of $10^{-4}$, we need
\begin{align} \frac{E_{\mathrm{RE}} - E_{\mathrm{RC}}}{k_BT} \approx -\ln\left( 5\times 10^{-6}\right) \approx 12. \end{align}So, the difference in the interaction between an erroneous and correct tRNA and the ribosome/mRNA complex would have to be at least $12k_BT$ (maybe more because some tRNAs are in higher abundance). So, the question is what is the energy difference between correctly and incorrectly bound tRNA-mRNA pairs and how does this compare to $12k_BT$? Being off by a single base pair could result in an erroneous amino acid being incorporated. The misalignment of the base pairs would result in disrupted hydrogen bonds. Base pairs have two or three hydrogen bonds. Presumably, at least one could form if the bases are misaligned. Thus, we could get an error with a single hydrogen bond being off. The stacking interactions are not as important here, since the bases are confined within the geometry of the ribosome. So, we will estimate that the energy difference is about one hydrogen bond, or $2k_BT$. So, there is just not enough energy in hydrogen bonding to give the necessary energy difference to give the low error rate.
Kinetic proofreading¶
Experimentally, it is known that there are intermediate steps in translation. In 1974, John Hopfield's big insight was that these steps require energy (e.g., GTP hydrolysis involving the elongation factor EF-Tu), and can therefore serve to decrease the error rate since the energy serves to overcome the limit set by thermodynamics. These hydrolysis events can cause a conformational change in the tRNA-codon complex that allow elongation and also for dissociation of tRNA from the codon. For this scheme, the chemical reactions are
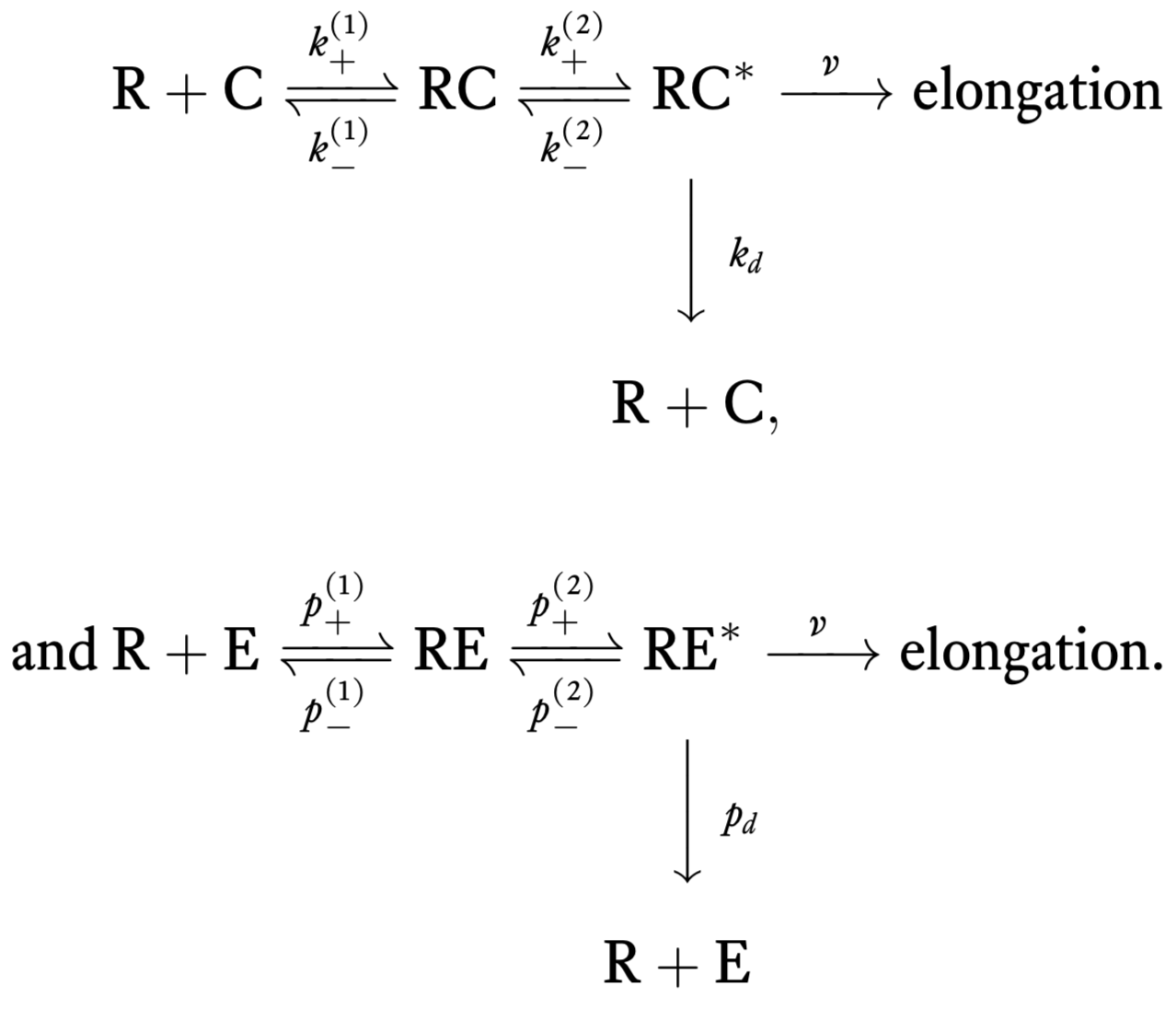
Error rate by kinetic proofreading¶
We will now compute the error rate for this new scheme. To begin, we compute the steady rate of elongation with correct amino acids, which we will call $r_c$. Our goal is to compute the steady state concentration of RC$^*$, $c^*$, since $r_c = v c^*$. Some differential equations describing the dynamics of the system under mass action kinetics are
\begin{align} &\frac{\mathrm{d}c_\mathrm{R}}{\mathrm{d}t} = -k_+^{(1)} c_\mathrm{R}\,c_\mathrm{C} + k_-^{(1)} c + k_dc^* \label{eq:ss_1}\\ &\frac{\mathrm{d}c}{\mathrm{d}t} = k_+^{(1)} c_\mathrm{R}\,c_\mathrm{C} - k_-^{(1)} c - k_+^{(2)}c + k_-^{(2)}c^*. \label{eq:ss_2} \end{align}Setting the time derivatives to zero, the first equation gives
\begin{align} c = \frac{1}{k_-^{(1)}}\,\left(k_+^{(1)}c_\mathrm{R}\,c_\mathrm{C} - k_dc^*\right). \end{align}Substituting this expression into the second equation (with the time derivative set to zero) yields
\begin{align} k_d c^* - \frac{k_+^{(2)}}{k_-^{(1)}}\,\left(k_+^{(1)}c_\mathrm{R}\,c_\mathrm{E} - k_dc^*\right) + k_-^{(2)}\,c^* = 0 \end{align}This is readily solved for $c^*$ to give
\begin{align} c^* = \frac{k_+^{(1)} k_+^{(2)} c_\mathrm{R}c_\mathrm{C}}{k_+^{(2)}k_d + k_-^{(1)}\left(k_-^{(2)} + k_d\right)}. \end{align}Similarly, we have for $e^*$,
\begin{align} e^* = \frac{p_+^{(1)} p_+^{(2)} c_\mathrm{R}c_\mathrm{E}}{p_+^{(2)}p_d + p_-^{(1)}\left(p_-^{(2)} + p_d\right)}, \end{align}giving an error rate of
\begin{align} f = \frac{r_e}{r_c} = \frac{e^*}{c^*} = q\left(\frac{p_+^{(1)} p_+^{(2)}}{k_+^{(1)} k_+^{(2)}}\right) \left(\frac{k_+^{(2)}k_d + k_-^{(1)}\left(k_-^{(2)} + k_d\right)}{p_+^{(2)}p_d + p_-^{(1)}\left(p_-^{(2)} + p_d\right)}\right). \end{align}Approximate error rate¶
For ease of comparison and to build intuition, we will consider the following approximations.
- The forward reactions of tRNA-codon binding have the same rate. That is to say, $k_+^{(1)} \approx p_+^{(1)}$. This would be expected if these reactions are diffusion limited, since both correct and erroneous tRNAs have the same diffusion coefficient.
- The dissociation of the activated complexes is much faster than their deactivation. This is essentially a statement of the irreversibility of the hydrolysis reaction. Mathematically, this means $k_-^{(2)} \ll k_d$ and $p_-^{(2)} \ll p_d$.
- The equilibrium prior to hydrolysis is fast; hydrolysis and conformational change are slow. Hence, $k_+^{(2)} \ll k_-^{(1)}$, and $p_+^{(2)} \ll p_-^{(1)}$.
- The hydrolysis reaction is nonspecific, such that $k_+^{(2)} \approx p_+^{(2)}$.
Applying approximation (2), we have
\begin{align} k_+^{(2)}k_d + k_-^{(1)}\left(k_-^{(2)} + k_d\right) \approx \left(k_-^{(1)} + k_+^{(2)}\right)k_d. \end{align}Applying approximation (3) gives
\begin{align} \left(k_-^{(1)} + k_+^{(2)}\right)k_d \approx k_-^{(1)} k_d. \end{align}Similar results hold for the terms describing erroneous binding. Thus, we have
\begin{align} f \approx q\,\frac{p_+^{(2)}}{k_+^{(2)}}\,\frac{k_-^{(1)}k_d}{p_-^{(1)}p_d}. \end{align}Applying approximation (1) allows us to write
\begin{align} f \approx q\,\frac{p_+^{(2)}}{k_+^{(2)}}\,\frac{K_{\mathrm{d},c}\,k_d}{K_\mathrm{c,e}\,p_d}, \end{align}since $K_{\mathrm{d},e} = p_-^{(1)} / p_+^{(1)} \approx p_-^{(1)} / k_+^{(1)}$. We use approximation (4), that the hydrolysis reaction is nonspecific such that $k_+^{(2)} \approx p_+^{(2)}$, giving
\begin{align} f \approx q\,\frac{k_d}{p_d}\,\frac{K_{\mathrm{d},c}}{K_{\mathrm{d},e}} = \frac{k_d}{p_d}\,f_0, \end{align}which is a $k_d/p_d$-fold improvement over the error rate without proofreading. So, to get improved fidelity, we need $k_d < p_d$; incorrectly paired complexes dissociate faster than correctly paired ones. To bring the error rate down four more orders of magnitude to the observed error rate, we would need this ratio to be about 1/10000.
Multiple steps enable greater selectivity¶
We have shown that adding the extra activation step allows for greater selectivity of correct amino acid incorporation in the context of translation. This extra step is a "proofreading" step that requires energy, hence the name kinetic proofreading. The kinetic proofreading principle is, in fact, more general. We have studied a recognition problem where there are two steps: bind a substrate and trigger a response. In this case, the substrate is tRNA and the response is addition of a new amino acid.
Kinetic proofreading has been applied extensively to recognition of major histocompatibility complex by T cell antigen receptors. The result of this recognition is T cell activation. This system exhibits extraordinary sensitivity, with the ability to detect a single ligand in a sea of thousands. This is better even than electronic circuits. In your homework, you will work out that this can be accomplished with many added steps of kinetic proofreading.